以太坊概述
比特币和以太坊是两种最重要的加密货币,比特币被称为区块链1.0,以太坊被成为区块链2.0
以太坊在系统设计上,针对比特币运行过程中出现的一些问题进行了改进,比如说出块时间调整至15s,这是基于ghost协议的共识机制;另外一个改进是挖矿使用的mining puzzle,比特币的mining puzzle是计算密集型的,比拼的是计算hash的算力,这样会造成挖矿设备的专业化,以太坊设计的是memory hard mining puzzle ,目的是在一定程度上限制ASIC芯片的使用(ASIC resistance),将来以太坊还有一些革命性的改变,用权益证明(proof of stake)代替工作量证明(proof of work)。除此之外,以太坊还加入了重要功能——对智能合约的支持(smart contract)。
什么是智能合约?
我们知道比特币是去中心化的货币(decentralized currency),而以太坊是去中心化的合约(decentralized contract)。货币本来由政府发行,货币的价值是建立在政府公信力的基础上,政府通过司法手段来维护货币系统的正常运行。比特币的出现用技术手段把政府的职能取代了。去中心化的合约也是类似的意思,现实社会中,合约的有效性也是应该通过政府维护的,以太坊也用技术手段取代了司法手段,如果合同中的内容可以通过代码实现,代码就可以放到区块链上,通过区块链的不可篡改性来保证代码的正确运行,当然,不是所有的合同都能用编程语言实现,也不是说所有的合同条款都可以量化,但是逻辑比较简单清晰的是可以写成智能合约的。
去中心化的合约的好处?
去中心化货币的一个应用场景是跨国转账,比如人民币→小币种,手续麻烦且手续费贵,如果用比特币就很方便。智能合约也有类似的应用场景,假如合同方来自世界各地,没有一个统一的司法管辖权,比较难用司法手段维护合约的有效性,这时候可以将合约内容以代码形式写进区块链里保证合约强制执行
以太坊账户
比特币是基于交易的账本,这种模式下并没有显式记录账户中有多少钱。
以太坊采用的是基于账户的模式,这种模式和银行账户比较类似,系统中要显示记录账户中有多少以太币,转账的时候只要余额够就可以转账,不用说明币的来源也不用找零,这样可以防御double spending attack。以太坊虽然不用说明币的来源,但是也不能篡改账户余额,因为账户余额在所有全节点的状态数中维护,必须所有全节点认为你的账户余额发生改变,你的账户余额才发生改变。虽然能防御double spending attack,但也可能会受到replay attack(重放攻击),转账的时候收款人是有恶意的,他可能会将这次交易再次发布,导致付款人转了两次。double spending attack 和 replay attack 是相对的,double spending 是花钱的人不诚实,replay attack 是收钱的人不诚实。以太坊解决replay attack的手段是加一个nonce(交易数),交易数代表这个账户建立以来的交易次数,由全节点维护,这个交易数会在交易过程成写进交易信息一起签名保护,如果交易的交易数比全节点中维护的付款人的交易数刚好大1,说明是正常交易,如果交易被重放的话,两者会相等,属于不合法交易。
以太坊中有两类账户,一类是外部账户(externally owned account),外部账户类似于比特币的账户,就是一对公私钥,掌握了私钥就掌握了这个账户。外部账户有两个状态,一个是balance,一个是nonce。第二类账户是合约账户(smart contract account),合约账户不是通过公私钥对控制,除了balance和nonce,还有code,storage。
以太坊状态树
以太坊采用的是基于账户的模式,系统中显式维护每个账户的余额
用什么数据结构来实现这种模式?
我们要完成的是账户地址到账户状态的映射,addr→state,以太坊用的账户地址是160bits,一般表示成40个十六进制数,状态是外部账户的状态和合约账户的状态,包括余额,交易数,对于合约账户,还包括代码和存储。
第一种方案,用hash表+merkle tree。从直观上看,映射就是一个key-value对,很自然的想法是用一个hash表来实现。系统中的全节点维护一个hash表,每次有一个新的账户插入到hash表里,查询账户的余额就查hash表,如果不考虑hash碰撞,查询速度可以在常数级别,更新也很方便。这种方案的问题是,以太坊要防止所有账户的state被篡改,就要像比特币一样构建一个merkle tree,里面的交易变成账户状态,如果每次发布一个合法交易,某个账户状态发生改变,那么每个全节点都要重新构造merkle tree,代价太大。
第二种方案,不用hash表,直接用merkle tree,修改的时候直接改merkle tree。这个方法的问题在于merkle tree没有提供高效的查找和更新的方法,另外不同节点构造的merkle tree 叶子节点顺序不同也会导致merkle root 不同 ,所以得用sorted merkle tree ,但是sorted merkle tree 也有问题,如果新创建的用户地址在hash值在中间,那么插入merkle tree之后,merkle tree几乎重构。
有一种数据结构叫trie(字典树或前缀树),从retrieval(检索)中来,下面是一个一些单词组织成一个trie的例子
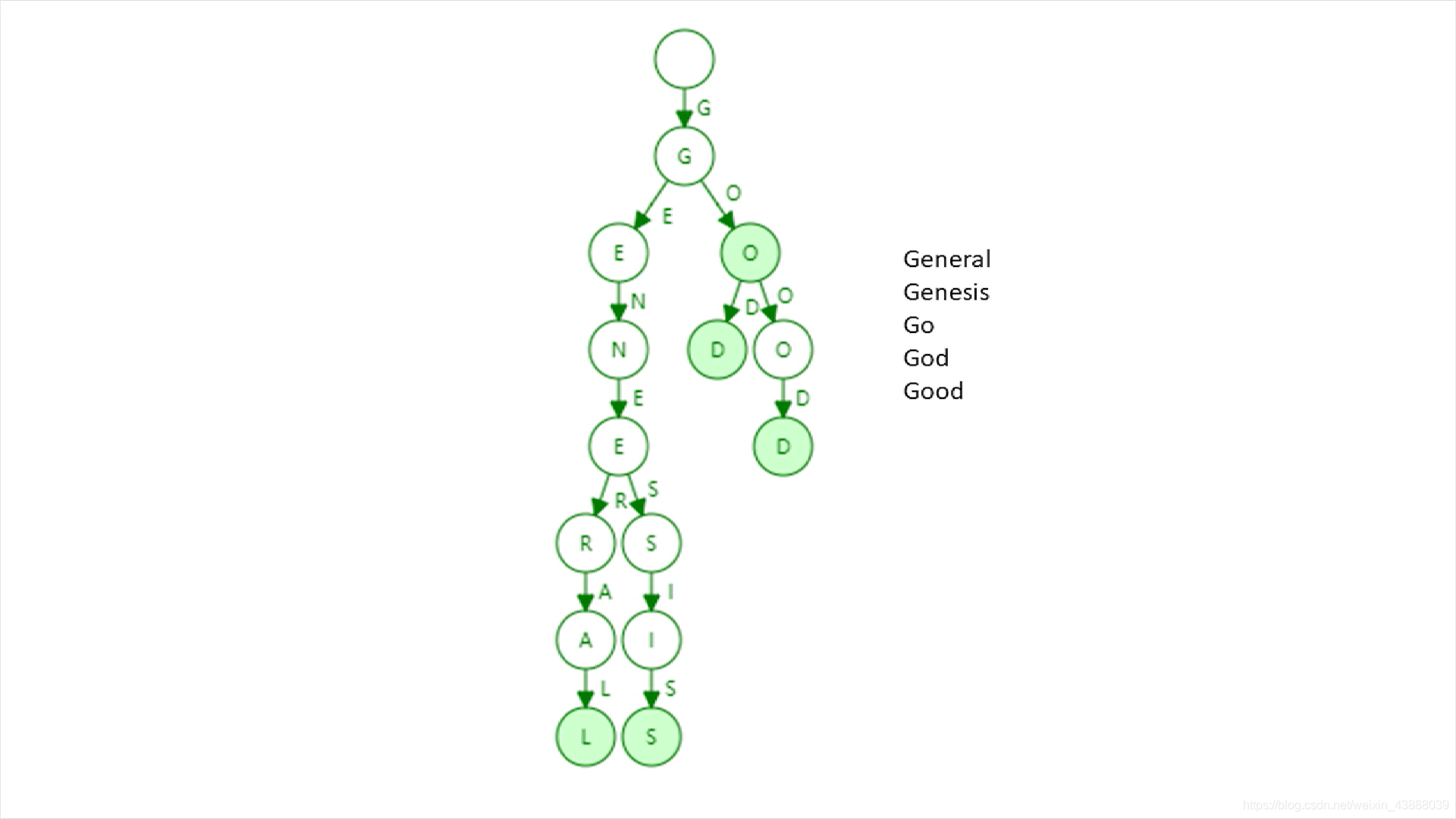
上图中,单词根据每一位的不同进行分裂,比如第二列有e和o就有两个分叉,第三列有在第二列是e的基础上只有n,所以只有一个分叉,单词有可能在非叶子节点结束。这个结构有一些特点。
第一个特点,在trie中,每个节点的分支数目取决于key中每个元素的取值范围,这个例子中,每个都是小写英文单词,所以每个节点的分叉数目最多27(26个小写字母+1个结束标志位)个,结束标志位表示到这个地方,这个单词就结束了。在以太坊中,地址是40位十六进制数,分叉数目有时候也叫branching factor 是17。
第二个特点,trie的查找效率取决于key的长度,键值越长,查找需要访问内存的次数就越多,以太坊中,键值都是40位。
第三个特点,如果用hash表存储key-value对,有可能出现碰撞,trie不会出现碰撞,只要地址不同,最后一定是不同分支
第四个特点,mekle tree不排序的话插入的账户位置不一样导致树的结构不一样,trie不论插入顺序如何,插入内容一致,最后的树就是一样的,这个对于以太坊非常有用
第五个特点,每次发布交易的时候,系统中大部分账户不变,只有少部分账户的状态需要更新,trie的局部更新性很好,只需要访问对应分支(注意,上图只画出了key)就可以找到value进行修改。
但是trie有一个缺点,trie的存储比较浪费,像上图有些节点只有一个子节点。如果能把这些节点合并,就可以减少存储的开销,也提高了查找的效率。
还有一种数据结构叫patricia tree或patricia trie(压缩前缀树),用上图例子进行路径压缩的结果如下
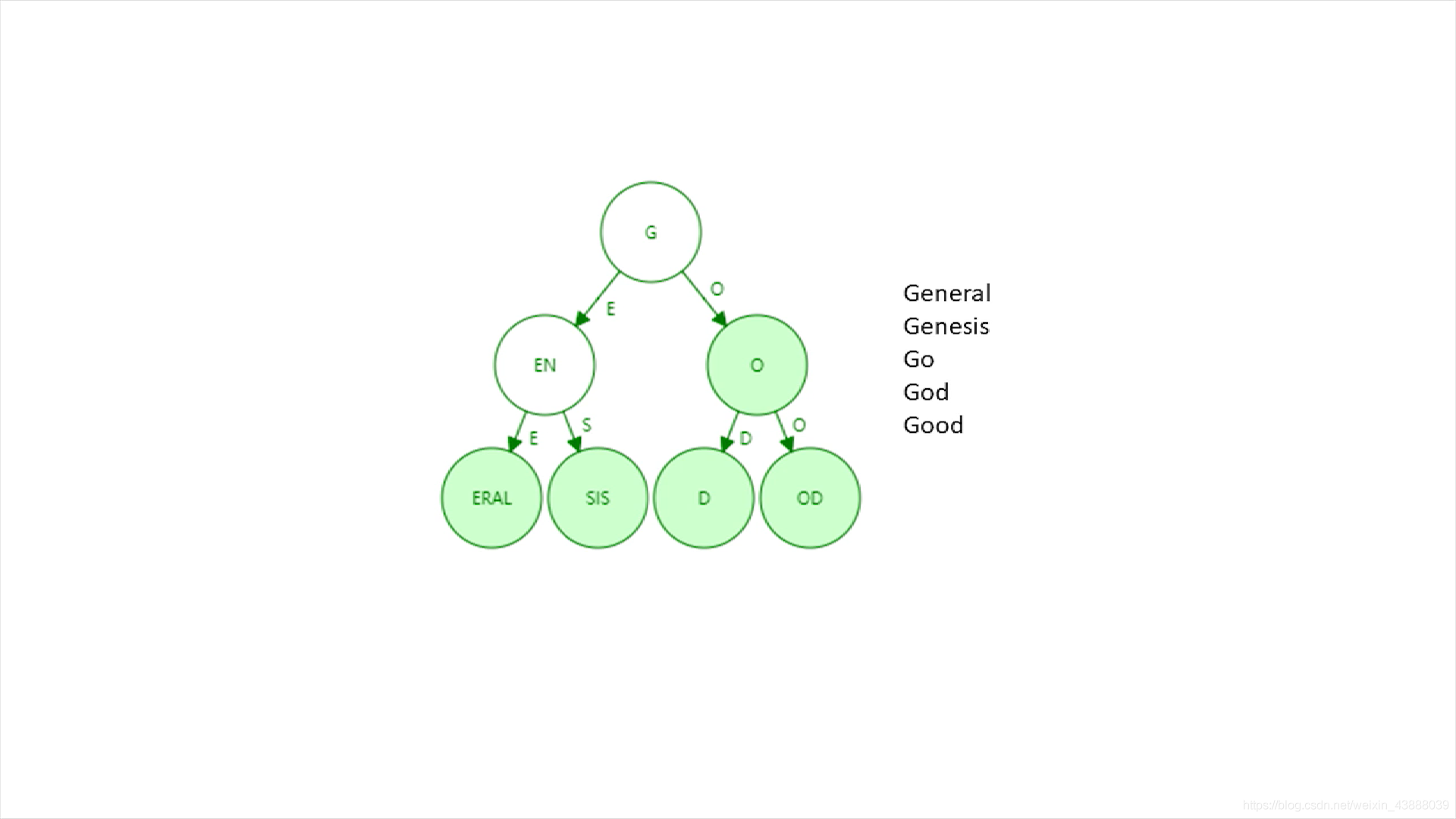
直观上看,树的高度减少了,存储更密集了。但是,如果新插入一个单词,原来压缩的路径可能需要扩展开来,假设上图加入geometry,就不能压缩成EN节点了。路径压缩有时候效果明显,有时候不明显。树中插入的键值分布如果比较稀疏情况下,路径压缩效果明显。比如假如上图的每个英文单词都很长,但是一共没有几个单词(misunderstanding、decentralized、disintermediation(去中心商,意思是让系统中的价值提供者和消费者直接交互)),这个时候插入到trie中,就会变成下图
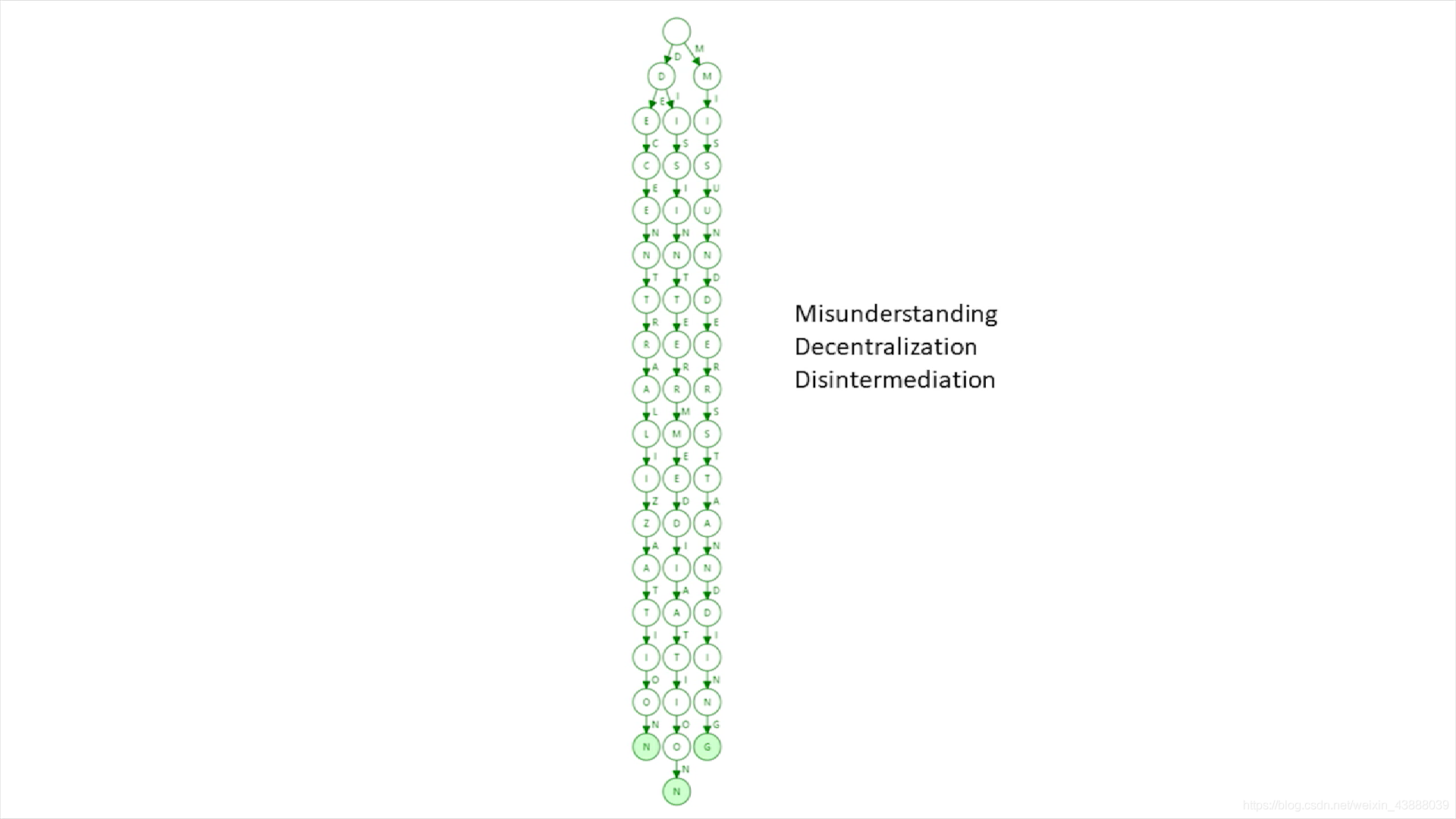
如果用了压缩树,就会变成
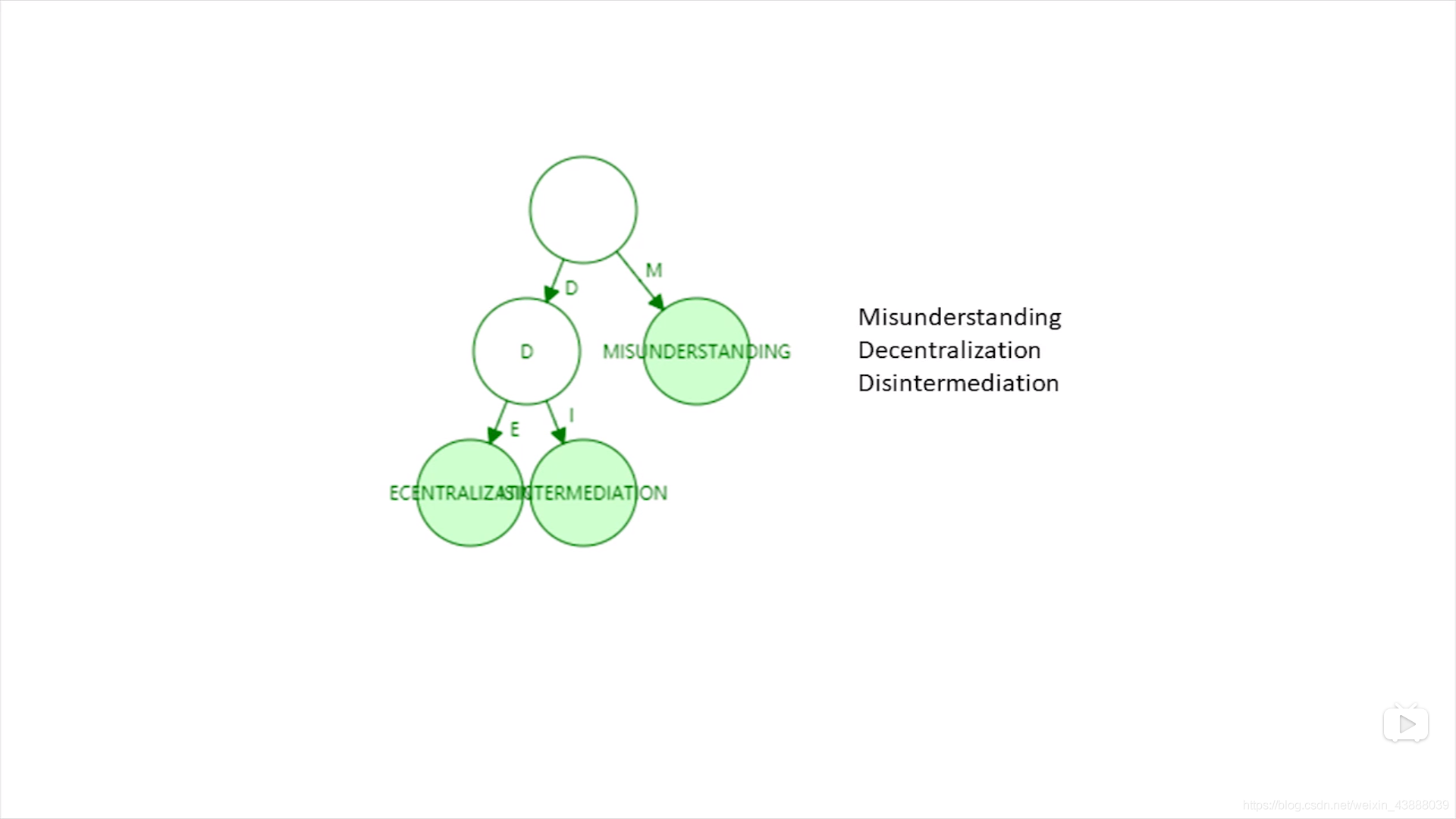
因此键值分布比较稀疏的时候,路径压缩效果较好。而在以太坊中,键值是地址,160位,总的地址空间有2160位,非常大。以太坊的账户数和2160相比微乎其微,所以键值分布非常稀疏
第三种方案 先提一下MPT(merkle patricia tree)。MPT和PT的区别就是连接节点之间的指针用的是hash指针,最后会保留一个关于状态树的merkle root,它的作用之一也是防止账户状态被篡改,作用之二是merkle proof证明账户余额,将账户状态所在分支发给轻节点即可证明,作用之三是证明账户不存在,如果账户存在,把应当存在的账户的所在分支发给轻节点验证,验证失败则不存在。以太坊的状态树用的就是MMPT(modified MPT),下图是一个例子。
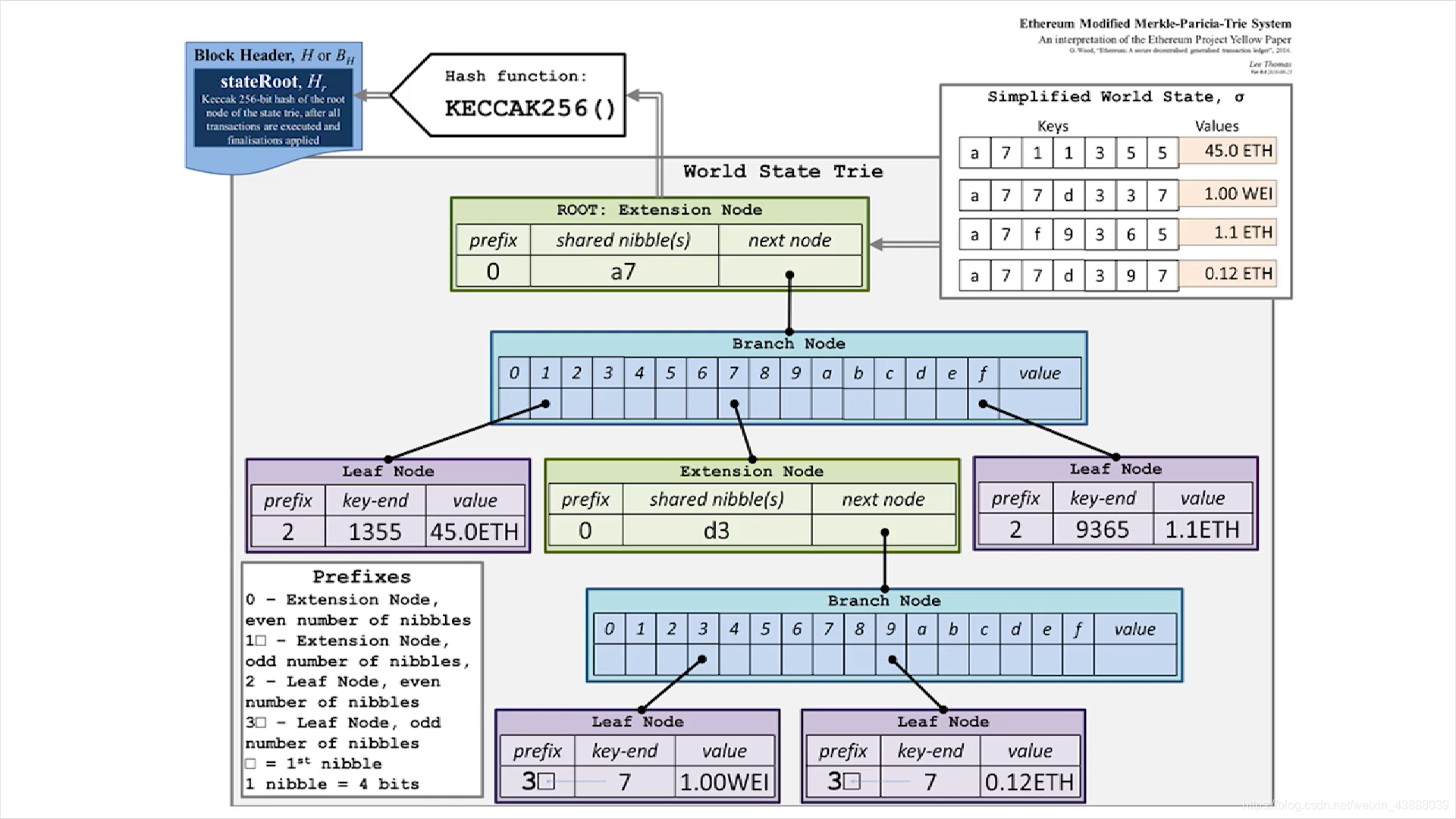
右上角有4个账户,为了简单起见,地址都非常短,就是上面的keys,账户状态只显示余额,就是上面的values。树中的节点分为三种,Extension Node,如果树的某一部位进行了压缩,就会出现一个Extension Node。因为4个地址的前两位开头都是a7,所以根节点就是Extension Node。下一层出现了分叉,所以出现了一个Branch Node。1的后面只有一个1355,所以它就是一个Leaf Node。7的后面有两个地址都是d3,所以压缩,再往下是3和9就分开来了,所以是一个Branch Node,再下面就是Leaf Node了。最右边的f后面就只有一个9365,所以是一个Leaf Node。
每次发布一个新的区块的时候,状态树中有一些节点的值会发生变化,这些改变不是原地修改,而是新建分支,原来的分支被保存。
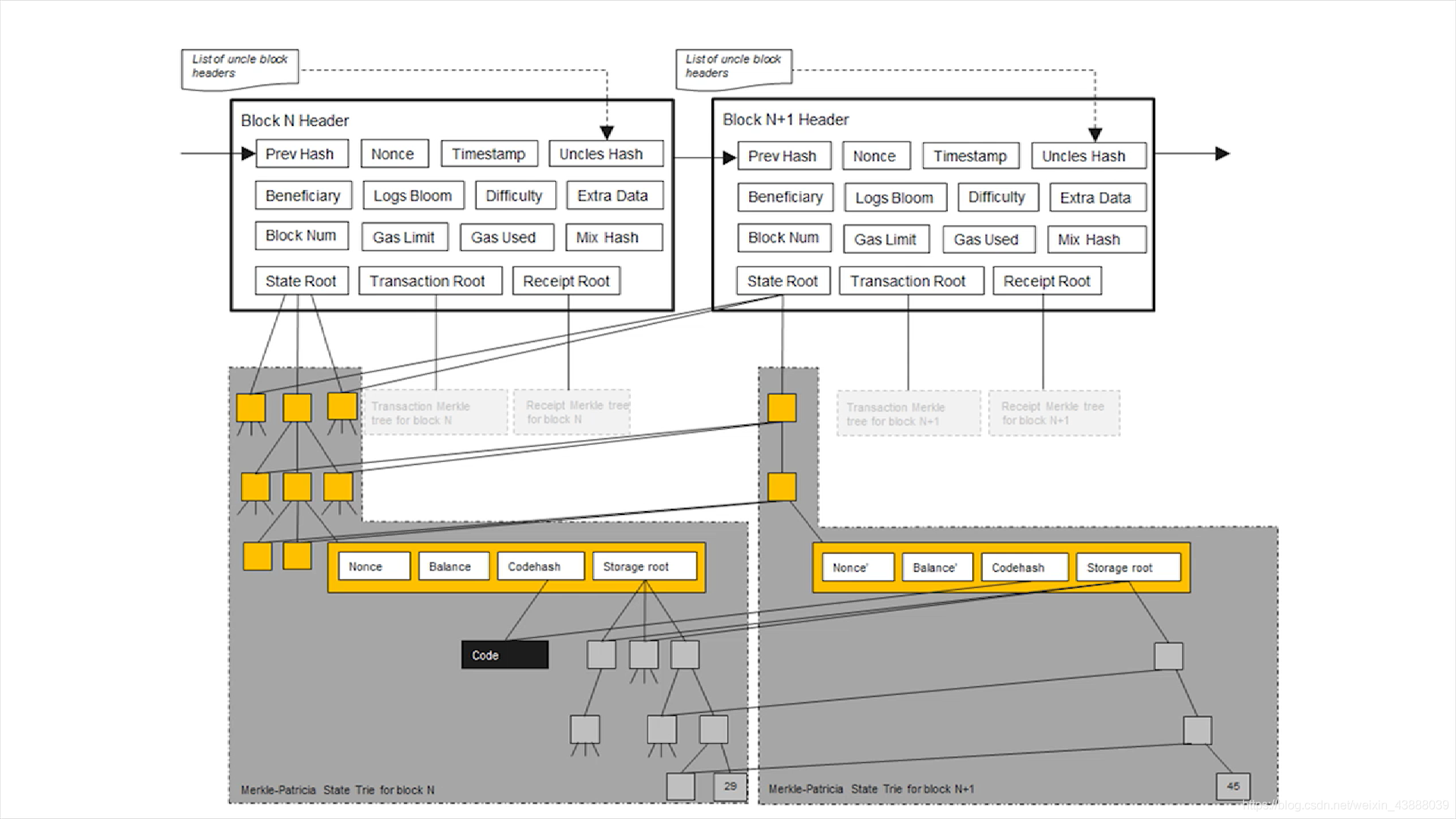
上图是两个相邻的区块,State Root是状态树的根hash值,虽然每一个区块只有一个State Root,但是两棵树的大部分节点是共享的,右边的树主要指向左边这棵树的节点,只有发生改变的节点需要新建分支。上图例子中是合约账户(包括nonce,balance,codehash,storage root的那个节点)发生变化,每一个合约账户的存储都是一棵小的MPT,上图交易次数nonce发生变化,balance发生变化,代码不变,所以codehash指向原来的code,存储变了,但是存储树中的大部分节点也是没有改变,唯一的改变的29变成了45,所以新建了一个分支。所以系统中要维护的不只是一颗MPT,而是每次出现一个区块,都要新建一个MPT,只不过这些状态树中大部分节点是共享的,只有少数发生变化的节点要新建分支。为什么要保留历史状态?系统当中有时候会出现分叉,临时性分叉非常普遍,假设出现一个分叉,两个节点同时获得记账权,如果上面一个节点胜出,下面的节点可以roll back(回滚对账户状态的修改)然后顺着上面的节点所在分支继续挖,这个和比特币不太一样,比特币交易类型比较简单,有的时候可以反向操作推断出前一个状态,比如说转账交易,A给B转了10个比特币,回滚只需要给A加10个比特币,B减去10个比特币,但是以太坊中不行,因为以太坊中有智能合约,智能合约执行完成后再推算之间的状态是不可能的,所以要想支持回滚就要记录历史状态。
以太坊中代码的数据结构!

上图是block header结构
ParentHash:前一个区块块头的hash
UncleHash:叔叔区块的hash,可能比Parent大好几辈
Coinbase:挖出区块的矿工地址
Root:状态树的根hash
TxHash:交易树的根hash,类似于比特币中的merkle root
ReceiptHash:收据树的根hash
Bloom:布隆过滤器,和收据树相关,提供高效的查询符合某种条件的交易的执行结果
Difficulty:挖矿难度
GasLimit和GasUsed和汽油费相关,智能合约消耗汽油费,类似于比特币中的交易费
Time:区块产生时间
MixDigest和Nonce和挖矿过程相关

上图是区块结构,header是指向block header的指针,uncles是指向叔叔区块的指针,而且是数组,transactions是交易列表

上图是区块在网上发布的真实结构,其实就是区块结构的前三项。
我们知道状态树保存的是key-value pairs,key就是地址,value是账户状态,账户状态要经过序列化过程才能保存进状态树中,序列化用的是RLP(Recursive Length Prefix),特点是简单,只支持nested array of bytes ,意思是字节数组可以嵌套,以太坊中所有数据类型最后都要变成nested array of bytes,
以太坊的交易树和收据树
每次发布的区块中,交易会组织成一棵交易树,也是一棵merkle tree,和比特币中情况类似;每个交易执行完之后会形成一个收据,记录交易的相关信息,交易树和收据树上的节点是一一对应的,增加收据树是考虑到以太坊的智能合约执行过程比较复杂,通过增加收据树的结构有利于快速查询执行结果。从数据结构上看,交易树和收据树都是MPT,和比特币有所区别,比特币的交易树就是普通的merkle tree ,MPT也是一种merkle tree,但是和比特币中用的不是完全一样。对于状态树来说,查找账户状态所用的key是地址,对于交易树和收据树来说,查找的键值就是交易在区块中的序号,交易的排列顺序由发布区块的节点决定。这三棵树有一个重要的区别,就是交易树和收据树都是只把当前发布的区块中的交易组织起来,而状态树是把系统中所有账户的状态都组织起来,不管账户和当前区块中的交易有没有关系。从数据结构上来说,多个区块的状态树是共享节点的,每次新发布的区块时,只有区块中的的交易改变了账户状态的那些节点需要新建分支,其它节点都沿用原来状态树上的节点。相比之下不同区块的交易树和收据树都是独立的。
交易树和收据树的作用
交易树一个用途是merkle proof ,像比特币中用来证明某个交易被打包到某个区块里。收据树也是类似的,证明某个交易的执行结果,也可以在收据树里提供一个merkle proof。除此之外,以太坊还支持更复杂的查询操作,比如查询过去十天当中和某个智能合约有关的交易,这个查询方法之一是,把过去十天产生的所有区块中交易都扫描一遍,看看哪些是和这个智能合约相关的,这种方法复杂度比较高,且对轻节点不友好。以太坊中的查询是引入了bloom filter(布隆过滤器),这个数据结构支持比较高效的查找某个元素是不是在一个比较大的集合里,bloom filter给一个大的集合计算出一个很紧凑的摘要,比如说一个128位的向量,向量初始都是0,通过hash函数,把集合中的每个元素映射到向量中的某个位置,元素的映射位置都置为1,所有元素处理完后向量就是一个摘要,这个摘要比原来的集合小很多。这个过滤器的作用是,我们想查询一个元素,但集合太大我们不能保存,这时候对该元素取hash值,发现映射到向量中0的位置,说明这个元素不在集合里,但是映射到向量中1的位置,也不能说明元素在集合里,因为可能会出现hash碰撞。所以用bloom filter时,可能会出现false positive,但是不会出现false negative,意思是有可能出现误报,但是不会出现漏报,在里面一定说在里面,不在里面可能也会说在里面。bloom filter有各种各样的变种,比如说像解决hash碰撞,有的bloom filter用的不是一个hash函数,而是一组,每个hash函数独立的把元素映射到向量中的某个位置,用一组hash函数的好处是,一般不可能一组hash函数都出现碰撞。bloom filter的一个局限性不支持删除操作,因为存在hash碰撞,使得不同元素映射到向量同一个位置,如果删掉一个元素,使对应位置上的1变成0,那么和它发生碰撞的元素也被删除了,所以简单的bloom filter 不支持删除操作,可以将0和1改成计数器,记录有多少元素映射过来,而且还要考虑计数器是否会overflow,但是这样就复杂的多,和当初设计的理念就违背了,所以一般用bloom filter就不支持删除操作。以太坊中bloom filter 的作用是,每个交易执行完成后会形成一个收据,收据里面就包含了一个bloom filter ,记录这个交易的类型、地址等其它信息,发布的区块在块头里也有一个总的bloom filter ,这个总的bloom filter 是区块里所有交易的bloom filter 的并集,所以说想查询过去十天当中和某个智能合约有关的交易,先查哪个区块的块头的bloom filter里有我要的交易的类型,如果块头的bloom filter里面没有,那么这个区块里面就没有我们想要的,如果块头的bloom filter 里有,我们再去查找区块里面包含的交易所对应的收据树里面对应的bloom filter,但是可能会出现误报,如果有的话,我们再找到相对应的交易进行确认,好处是通过bloom filter能快速过滤大量无关区块,很多区块看块头的bloom filter就知道没有我们想要的交易,剩下的少数候选区块再仔细查看。轻节点只有块头信息,根据块头就能过滤掉很多信息,剩下有可能是想要的区块,问全节点要具体信息。
以太坊的运行过程可以看作交易驱动的状态机(transaction-driven state machine),状态机的状态指状态树中的那些账户状态,交易指交易树中那些交易,通过执行这些交易,使得系统从当前状态转移到下一个状态。比特币也可以认为是交易驱动的状态机,比特币中的状态是UTXO。这两个状态机有一个共同特点是状态转移都是确定性的,对一组给定的交易能够确定性的驱动系统转移到下一个状态,因为所有的节点都要执行同样的交易,所以状态转移必须是确定性的。
以太坊挖矿算法
对于基于工作量证明的区块链系统来说,挖矿是保障安全的重要手段。为了抵制矿机,以太坊设计了一中memory hard mining puzzle,以太坊用了两个数据集,一个是16M的cache,一个是1G的dataset叫做DAG,DAG是从cache中生成,这样设计的目的是便于轻节点验证,轻节点只需要保存16M的cache即可,只有矿工才需要保存1G的大数据集。基本思想是先用一个种子节点经过一些运算得到数组的第一个元素,然后对元素依次取hash得到后面的元素,这样得到的是一个填充了伪随机数的数组,就是一个cache,然后大数据集里面的每一个元素根据cache里的元素,依次读取256次取hash生成,求解puzzle的时候用的是大数据集,按照伪随机的顺序从大数据集中读取128个数,一开始,根据区块的块头算出一个初始的hash,根据hash映射到大数据集中的某个位置,把该数读取出来,然后进行运算得到下一个数得位置,每次读取的时候除了计算出这个元素的位置之外,还要把相邻的元素读取出来,进行64次循环,每次取出2个数,得到128个数,最后算出一个hash值,和挖矿难度的目标阈值比较一下,如果不合适就将block header里面的nonce替换一下重复上面过程
权益证明
比特币和以太坊目前用的都是基于工作量的证明,这种共识机制受到普遍的批评就是浪费电。
矿工挖矿是出于出块奖励,算力越大,出块奖励平均下来就越大,算力取决于设备的多少,也就是资金的投入,资金投入越多,奖励也越丰厚。那么我们可不可以不挖矿,直接比拼资金,奖励按资金比分配?这就是权益证明的思想,权益证明有时候也叫virtual mining。
采用权益证明的交易货币,一般会在正式发行之前预留一些货币给开发者,也会出售一部分货币来换取开发加密货币所需要的资金,将来按照权益证明的共识机制,每个人按照持有货币的数量进行投票,这种方法和工作量证明相比有一些优点,一个是不需要挖矿了,减少能耗;二是挖矿的算力从现实世界来,攻击者只要足够富裕,买大量矿机就可以发动攻击,对于小币种是致命打击,权益证明是按持有的货币数量进行投票,类似股票分红,如果某人想发动攻击,他需要先获得货币总量的51%才能发动攻击,也就是说发动攻击的资源必须从加密货币的系统中来,这样就系统形成了一个闭环,无论攻击者在系统外有多少资源,都不会对系统造成直接的影响,如果一定要发动攻击就要买大量的币,造成币的大涨,而开发者和早期矿工就可以从中获利。权益证明和工作量证明不是互斥的,有些加密货币采用的是混合模型,仍然要挖矿,但是挖矿难度和持有多少币是相关的,币越多难度越低,但是这样简单设计有一个问题就是富人挖矿越来越简单。有些两者混用的加密货币系统会将用于降低挖矿难度的币锁定一段时间,下次再挖一个区块的时候,不能用锁定的币降低难度,过几个区块才能使用,这种叫proof of deposit。
权益证明有许多问题,早期的权益证明有一个问题是两边下注
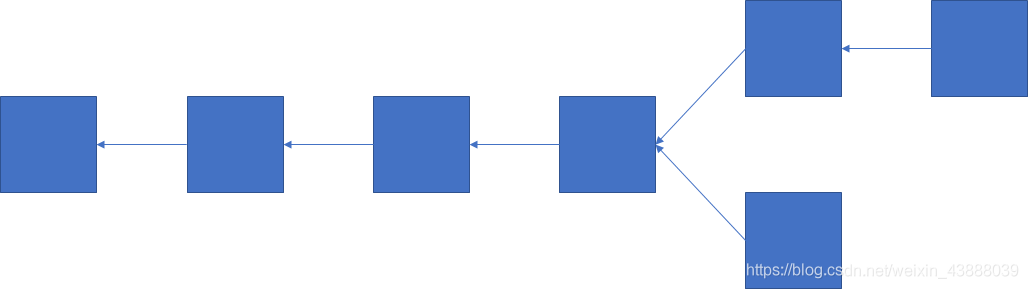
上图出现分叉,如果挖矿的话,我们会沿着上面这条链继续挖,但是下面的链也有可能成为最长合法链,只要下面这个分支连续挖出好几个区块。但是矿工不会两边都挖,因为算力会分散。如果不挖矿,用权益证明的话,两边都可以下注,如果上面那条链成为最长合法链,下面分支锁定的币对上面分支没有影响的,所以这种情况叫nothing at stake。
以太坊准备采用的权益证明协议叫做Casper the Friendly Finality Gadget(FFG),它在过渡阶段也是要和工作量证明混合使用,为工作量证明提供finality,finality 是最终状态,包含在finality中的交易不会被取消,单纯基于工作量证明是有可能被回滚的,Casper协议引入validator,要想成为validator,必须投入一定数量的以太币作为保证金,这个保证金会被锁定,validator推动系统达成共识,投票决定哪条链是最长合法链,投票权重取决于保证金的大小。挖矿的时候(混用状态下)每挖出一百个区块,就作为一个epoch,然后要决定它能不能成为finality要进行投票,投票进行两轮,类似于数据库的two-phrase commit,一个是prepare message,一个是commit message,Casper规定每一轮投票都要获得2/3以上的投票才能通过。实际当中不区分投票阶段,epoch也减少至50个,每个epoch只用一轮投票就行,这轮投票对于上一个epoch来说是commit message,对于下一个epoch来说是prepare message,要连续两个epoch都得到2/3的投票才算有效。
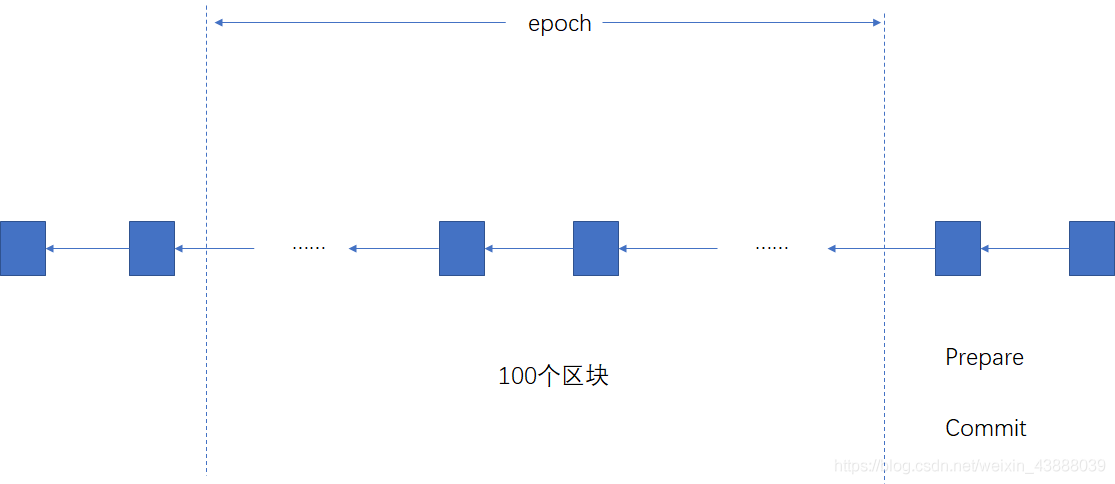
上图是早期的Casper协议,100个区块构成一个epoch,每个epoch要投两轮,都要获得2/3的票
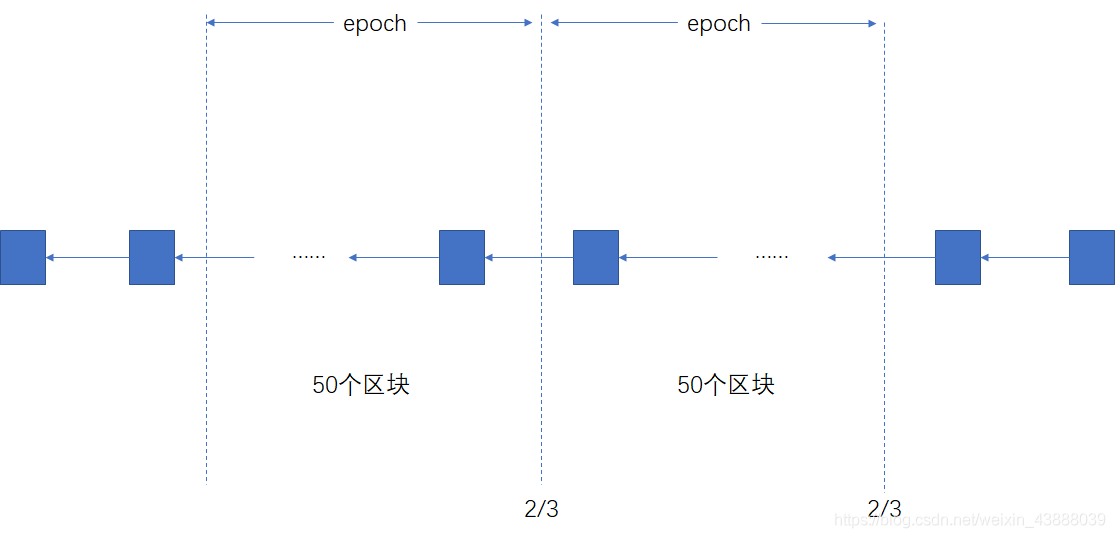
上图是实际的Casper,这轮投票对于上一个epoch来说是commit message,对于下一个epoch来说是prepare message,要连续两个epoch都得到2/3的投票才算通过。
验证者验证的好处是如果验证者履行职责,那么可以获得相应的奖励,就像矿工挖矿能获得出块奖励一样,验证者验证也可以得到奖励,相反,如果验证者有不良行为,要受到相应处罚,比如验证者不作为,导致系统迟迟达不成共识,这样要扣掉验证者的部分保证金,如果验证者乱作为,给两个有冲突的分叉都投票,这种情况要没收全部的保证金。没收的保证金会销毁,相当于减少了以太币的总量。每个验证者有一定的任期,任期满了之后要经过一定时间的等待期,等待期是为了让其它节点可以检举验证者的不良行为,等待期过了没有受到惩罚那么验证者可以取回保证金以及一定的奖励,这就是casper协议的过程。
这里有一个问题,包含在finality的交易是不是一定不会被回滚,假设有某个恶意节点发动攻击,如果他只是一个矿工,那么他是不能推翻已经达成的finality,因为finality是验证者投票投出来的。如果有大量的验证者两边下注,给前后两个有冲突的finality都下注,casper协议规定每轮投票要2/3的支持才算通过,所以至少有1/3的验证者是两条分叉都投票了。

